 git原理
git原理
# git 原理
Git 是一个内容寻址文件系统。这意味着,Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索该内容。而这些数据全部是存储在objects目录里。key是一个hash, hash前两个字符用于命名子目录,余下的 38 个字符则用作文件名。如果了解tree 树的朋友应该会想明白之所以这样处理是因为检索优化策略,提高文件系统效率(如果把太多的文件放入同一个目录中,一些文件系统会变慢)。而这个hash的内容(即hash对应的Value)有四种对象类型,commit(提交),tree(目录树),,blob(块),tag(标签)。
从根本上来讲,Git是一个内容寻址的文件系统,其次才是一个版本控制系统。记住这点,对于理解Git的内部原理及其重要。所谓“内容寻址的文件系统”,意思是根据文件内容的hash码来定位文件。这就意味着同样内容的文件,在这个文件系统中会指向同一个位置,不会重复存储。
# Git 到底是如何工作呢 ?
在 Git 的设计中,有两种命令:分别是底层命令(Plumbing commands)和高层命令(Porcelain commands)。一开始,Linus 就设计了这些给开源社区黑客使用的符合 Unix KISS 原则的命令,因为黑客们本身就是动手高手,水管坏了就撸起袖子去修理,因此这些命令被称为 plumbing commands. 后来接手 Git 的 Junio Hamano 觉得这些命令对于普通的用户可不太友好,因此在此之上,封装了更易于使用、接口更精美的高层命令,也就是我们今天每天使用的 git add, git commit 之类。
我们知道最简单的git flow主要有三步
- 在工作目录中修改文件。
- 暂存文件,将文件的快照放入暂存区域。
- 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录。
在我们看这三个命令到底做了什么之前,先来了解一下几个概念
以为git是一个分布式版本控制系统,因此git的操作大部分都是在本地,除非明确说明下面的原理或者命令都是在本地操作。
每个git项目的根目录下都有一个.git目录,它是git默默进行版本控制时读写的“数据库”。有几个概念需要提一下:
--工作区:代码所在的目录,就是自己电脑中能够看到的目录
--暂存区:英文叫stage或者index。一般存放在.git/index文件中,所以我们把暂存区也叫作索引index
--版本库:工作区有一个隐藏的.git,这个不算工作区,而是Git的本地版本库,你的所有版本信息都会存在这里
# 对象数据库
Git 最核心、最底层 的部分则是其所实现的一套 对象数据库(Object Database),其本质是一个基于 Key-Value 的内容寻址文件系统(Content-addressable File System)。笔者认为其设计理念与传统的文件系统的设计理念极其相似,为了方便理解和对照,因此在下文中,我们将以 Git 文件系统 作为简称。
Git 文件系统中存储了所有文件的所有历史快照,通过索引不同的历史快照,Git 才能够实现版本控制。下面,我们来介绍一下 Git 文件系统。
# 对象模型
通过对比 Git 文件系统和 Ext 文件系统,我们基本了解了 Git 是如何存储和索引文件及目录的。接下来,我们来深入了解 Git 的对象模型,即数据存储的基本单元及类型。
Git 对象模型主要包括以下 4 种对象
二进制对象(Blob Object)
树对象(Tree Object)
提交对象(Commit Object)
标签对象(Tag Object) 所有对象均存储在 .git/objects/ 目录下,并采用相同格式进行表示,其可以分为两部分:
头部信息:类型 + 空格 + 内容字节数 + \0
存储内容 Git 使用两部分内容的 40 位 SHA-1 值(前 2 为作为子目录,后 38 位作为文件名)作为快照文件的唯一标识,并对它们进行 zlib 压缩,然后将压缩后的结果作为快照文件的实际内容进行存储。
下面,我们来主要介绍一下其中前三种对象类型。
# Blob Object
Block Object 用于存储普通文件的内容数据,其头部信息为 "blob" + 空格 + 内容字节数 + \0,存储内容为对应文件的内容快照。
# Tree Object
Tree Object 用于存储目录文件的内容数据,其头部信息为 "tree" + 空格 + 内容字节数 + \0,存储内容为 一个或多个树对象记录(Tree Entry)。
其中,树对象记录的结构(Git v2.0.0)为:文件模式 + 空格 + 树对象记录的字节数 + 文件路径 + \0 + SHA-1。
注意,当我们执行 git add(进入暂存区)时,Git 会为暂存文件创建 Blob Object,为暂存目录创建 Tree Object ,结合未修改文件和目录的 Object,建立一个整体的索引关系,从而形成一个版本快照。
# Commit Object
Tree Object 和 Blob Object 用于表示版本快照,Commit Object 则不同,它 用于表示版本索引和版本关系。
此外,Tree Object 和 Blob Object 的 SHA-1 值是根据内容计算得到的,只要内容相同,SHA-1 值相同;而 Commit Object 会结合内容、时间、作者等数据,因此 SHA-1 值很难出现冲突。
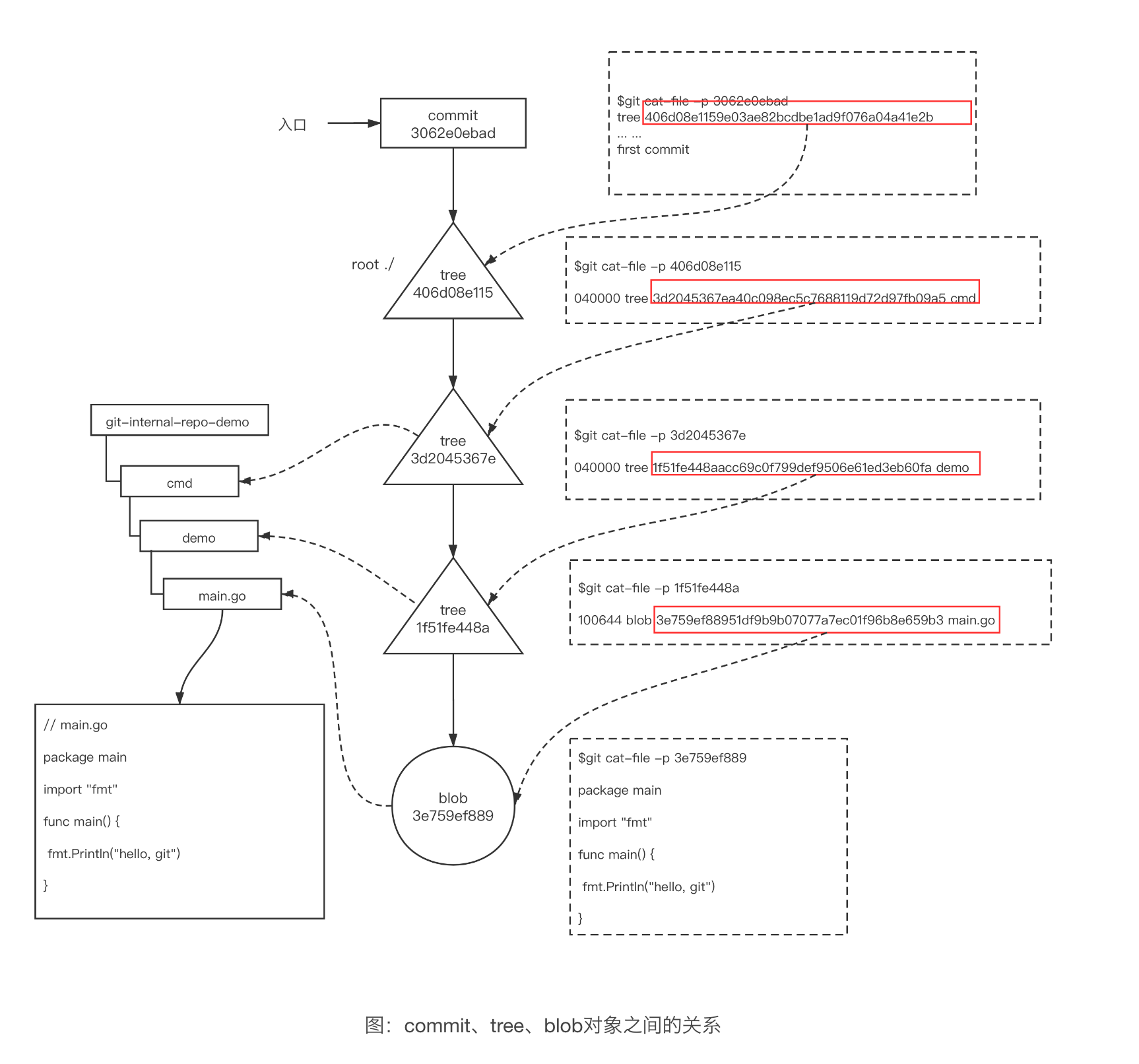
Commit Object 的头部信息为 "commit" + 空格 + 内容字节数 + \0,存储内容包含多个部分(Git v2.0.0),具体如下图所示。
对应的根 Tree Object 对应的 SHA-1
一个或多个父级 Commit Object 对应的 SHA-1。当进行分支合并时就会出现多个父级 Commit Object。
提交相关内容,包括:作者信息、提交者信息、编码、提交描述等
# 每个commit都是一个git仓库的快照
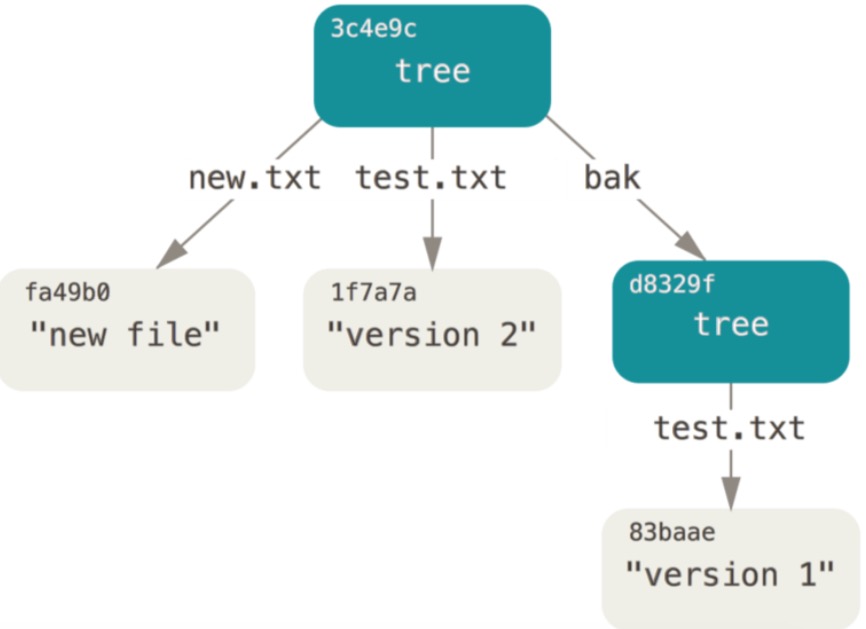
要理清objects“筐”中各object间的关系,就必须要把握住一个关键概念:“每个commit都是git仓库的一个快照” – 以一个commit为入口,我们能将当时objects下面的所有object联系在一起。因此,上面5个object中的那个commit对象就是我们分析各object关系的入口。我们根据上述5个object的内容将这5个object的关系组织为下面这幅示意图:
通过上图我们看到:
注意
commit是对象关系图的入口;
tree对象用于描述目录结构,每个目录节点都会用一个tree对象表示。目录间、目录文件间的层次关系会在tree对象的内容中体现;
每个commit都会有一个root tree对象;
blob对象为tree的叶子节点,它的内容即为文件的内容。
和subversion这样的集中式版本管理工具最大的不同就是每个程序员节点都是git仓库,拥有全部开发、协作所需的全部信息,完全可以脱离“中心节点”;
如果说git聚焦于数据平面的功能,那么github则是一个基于git网络协作的控制平面的实现;
objects是个筐,什么都往里面装。git仓库的核心数据都存在.git/objects下面,主要类型包括:blob、tree和commit;
每个commit都是一个git仓库的快照,记住commit对象是分析对象关系的入口;
git是基于数据内容的hash值做等值判定的,object是不可变的,默克尔树(Merkle Tree)用来快速判断变化。
branch和tag因为是“指针”,因此创建、销毁和切换都非常轻量。
每个commit对象都是一个git仓库的快照,切换到(git checkout xxx)某个branch或tag,就是将本地工作拷贝切换到commit对象所代表的仓库快照的状态。当然也会将commit对象组成的单向链表的head指向该commit对象,这个head即.git/HEAD文件的内容。