 内存管理自我总结
内存管理自我总结
# 什么是内存管理
是指软件 (opens new window)运行时对计算机内存 (opens new window)资源的分配和使用的技术。其最主要的目的是如何高效、快速的分配,并且在适当的时候释放和回收内存资源
体现在iOS的内存管理,就是对对像引用计数的管理
# Objective-C 中的内存分配
在 Objective-C 中,对象通常是使用 alloc 方法在堆上创建的。 [NSObject alloc] 方法会在对堆上分配一块内存,按照NSObject的内部结构填充这块儿内存区域。
一旦对象创建完成,就不可能再移动它了。因为很可能有很多指针都指向这个对象,这些指针并没有被追踪。因此没有办法在移动对象的位置之后更新全部的这些指针。
# MRC 与 ARC
Objective-C中提供了两种内存管理机制:MRC(MannulReference Counting)和 ARC(Automatic Reference Counting),分别提供对内存的手动和自动管理,来满足不同的需求。现在苹果推荐使用 ARC 来进行内存管理。
ARC和MRC是iOS中两种不同的内存管理机制。ARC是自动引用计数,由编译器在编译时自动插入内存管理代码,而MRC是手动引用计数,开发者需要手动管理对象的引用计数。
# 什么是引用计数,原理是什么?
引用计数可以有效的管理对象的生命周期。当我们创建一个新的对象的时候,它的引用计数为1,当有一个新的指针指向这个对象的时候,我们将其引用计数加1,当某个指针不再指向这个对象时,我们将其引用计数减1,当对象的引用计数变为0时,说明这个对象不再被任何指针指向了,这个时候我们就可以将对象摧毁,回首内存。
由于引用计数简单有效,出来oc语言外,微软的COM(Component Object Model)、C++11(C++11提供了引用计数的智能指针share_prt)等语言也提供了基于引用计数的内存管理方式。
# 为什么需要引用计数?
引用计数真正派上用场的场景是在面向对象的程序设计架构中,用于对象之间的传递和共享数据。我们举个栗子看一下:
假如对象A生成了一个对象M,需要调用对象B的某一个方法,将对象M作为参数传递过去。在没有引用计数的情况下,一般内存管理的原则是“谁申请谁释放”,那么对象A就需要在对象B不再需要对象M的时候,将对象M摧毁掉。但对象B可能只是临时用一下对象M,也可能觉得对象M很重要,将它设置成自己的一个变量,在这种情况下,什么时候摧毁对象M就成为一个难题了

方案一:
这种情况,有一种很黄很暴力的做法,就是对象A在调用完对象B之后,马上销毁参数对象M,然后对象B需要将参数另外复制一份,生成另一个对象M2,然后自己管理对象M2的生命期。但是这种做法有一个很大的问题,就是它会带来更多的内存申请、复制、释放的工作。本来一个可以复用的对象,因为不方便管理它的生命期,就简单的把它摧毁,又重新构造一份一样,真的影响性能。

方案二:
我们还有另外一种方法,就是对象A在构造完对象M之后,始终不销毁对象M,由对象B来完成对象M的销毁工作。如果对象B需要长时间使用对象M,就不销毁它,如果只是临时用一下,就可以马上销毁。这种做法看似很好的解决了对象复制的问题,但是它强烈的依赖于A、B两个对象的配合,代码维护者需要明确的记住这种编程的约定。而且,由于对象M的申请是在对象A中,而释放在对象B中,使得它的内存管理代码分布在两个对象中,管理起来也是废了老逼劲了。

如果这个时候,情况在复杂一些,举个恶心的栗子,对象B需要再向对象C传递对象M,那么这个对象在对象C中又不能让对象C管理。所以这种方式带来的复杂性更加大,不可取。 所以,bb了这么多,就想说引用计数很好的解决了这个问题,在参数M传递的过程中,哪些对象需要长时间使用这个对象,就把它的引用计数加1,使用完了再把引用计数减1.所有的对象都遵循这个规则的话,对象的生命期的管理工作就完全交给了引用计数 了,成功甩锅。我们也可以很方便的享受到共享对象带来的快感和好处。
所以,bb了这么多,就想说引用计数很好的解决了这个问题,在参数M传递的过程中,哪些对象需要长时间使用这个对象,就把它的引用计数加1,使用完了再把引用计数减1.所有的对象都遵循这个规则的话,对象的生命期的管理工作就完全交给了引用计数 了,成功甩锅。我们也可以很方便的享受到共享对象带来的快感和好处。
引用计数存在哪
Tagged Pointer不需要引用计数NONPOINTER ISA(isa的第一位为1)的引用计数优先存在isa中,大于524288了进位到Side Tables- 非
NONPOINTER ISA引用计数存在Side Tables
retain/release的实质
- 找到引用计数存储区域,然后+1/-1
- 如果是
NONPOINTER ISA,还要处理进位/借位的情况 - release在引用计数减为0时,调用
dealloc
# iOS的内存管理方案有三种
# 方案一.tagged pointer(NSNumber、NSDate、NSString)
没有这种管理机制会引起内存浪费,为什么呢?我们来看下,假设我们要存储一个NSNumber对象,其值是一个整数。正常情况下,如果这个整数只是一个NSInteger的普通变量,那么它所占用的内存是与CPU的位数有关,在32位CPU下占4个字节,在64位CPU下是占8个字节的。而指针类型的大小通常也是与CPU位数相关,一个指针所占用的内存在32位CPU下为4个字节,在64位CPU下也是8个字节。
所以一个普通的iOS程序,如果没有Tagged Pointer对象,从32位机器迁移到64位机器中后,虽然逻辑没有任何变化,但这种NSNumber、NSDate一类的对象所占用的内存会翻倍。
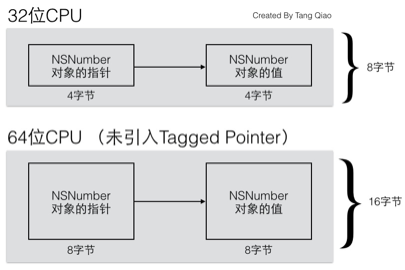
我们再来看看效率上的问题,为了存储和访问一个NSNumber对象,我们需要在堆上为其分配内存,另外还要维护它的引用计数,管理它的生命期。这些都给程序增加了额外的逻辑,造成运行效率上的损失。
为了改进上面提到的内存占用和效率问题,苹果提出了Tagged Pointer对象。由于NSNumber、NSDate一类的变量本身的值需要占用的内存大小常常不需要8个字节,拿整数来说,4个字节所能表示的有符号整数就可以达到20多亿(注:2^31=2147483648,另外1位作为符号位),对于绝大多数情况都是可以处理的。
所以我们可以将一个对象的指针拆成两部分,一部分直接保存数据,另一部分作为特殊标记,表示这是一个特别的指针,不指向任何一个地址。所以,引入了Tagged Pointer对象之后,64位CPU下NSNumber的内存图变成了以下这样:
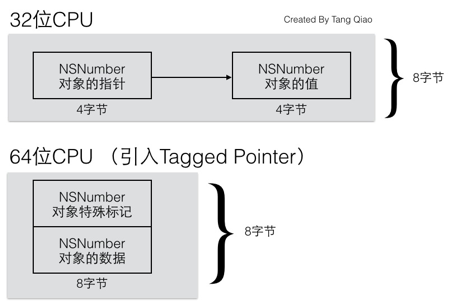
当8字节可以承载用于表示的数值时,系统就会以Tagged Pointer的方式生成指针,如果8字节承载不了时,则又用以前的方式来生成普通的指针。以上是关于Tag Pointer的存储细节。
Tagged Pointer的特点:
我们也可以在WWDC2013的《Session 404 Advanced in Objective-C》视频中,看到苹果对于Tagged Pointer特点的介绍:Tagged Pointer专门用来存储小的对象,例如NSNumber和NSDate, 当然NSString小于60字节的也可以运用了该手段
Tagged Pointer指针的值不再是地址了,而是真正的值。所以,实际上它不再是一个对象了,它只是一个披着对象皮的普通变量而已,因为他没有isa指针。所以,它的内存并不存储在堆中,也不需要malloc和free。
在内存读取上有着3倍的效率,创建时比以前快106倍。
由此可见,苹果引入Tagged Pointer,不但减少了64位机器下程序的内存占用,还提高了运行效率。完美地解决了小内存对象在存储和访问效率上的问题。
Tagged Pointer 的引用主要解决内存浪费和访问效率的问题。
# 方案二、Non-pointer iSA--非指针型iSA
在64位系统上只需要32位来储存内存地址,而剩下的32位就可以用来做其他的内存管理
non_pointer iSA 的判断条件:
1 : 包含swift代码;
2:sdk版本低于10.11;
3:runtime读取image时发现这个image包含__objc_rawi sa段;
4:开发者自己添加了OBJC_DISABLE_NONPOINTER_ISA=YES到环境变量中;
5:某些不能使用Non-pointer的类,GCD等;
6:父类关闭。
# 方案三、SideTables,RefcountMap,weak_table_t
为了管理所有对象的引用计数和weak指针,苹果创建了一个全局的SideTables,虽然名字后面有个"s"不过他其实是一个全局的Hash表,里面的内容装的都是SideTable结构体而已。它使用对象的内存地址当它的key。管理引用计数和weak指针就靠它了。
因为对象引用计数相关操作应该是原子性的。不然如果多个线程同时去写一个对象的引用计数,那就会造成数据错乱,失去了内存管理的意义。同时又因为内存中对象的数量是非常非常庞大的需要非常频繁的操作SideTables,所以不能对整个Hash表加锁。苹果采用了分离锁技术。
下边是SideTabel的定义:
SideTable
struct SideTable {
//锁
spinlock_t slock;
//强引用相关
RefcountMap refcnts;
//弱引用相关
weak_table_t weak_table;
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
当我们通过SideTables[key]来得到SideTable的时候,SideTable的结构如下:
1、一把自旋锁。spinlock_t slock;
自旋锁比较适用于锁使用者保持锁时间比较短的情况。正是由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用,而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。
它的作用是在操作引用技术的时候对SideTable加锁,避免数据错误。
苹果在对锁的选择上可以说是精益求精。苹果知道对于引用计数的操作其实是非常快的。所以选择了虽然不是那么高级但是确实效率高的自旋锁
*2、引用计数器 RefcountMap refcnts;
对象具体的引用计数数量是记录在这里的。
这里注意RefcountMap其实是个C++的Map。为什么Hash以后还需要个Map呢?因为内存中对象的数量实在是太庞大了我们通过第一个Hash表只是过滤了第一次,然后我们还需要再通过这个Map才能精确的定位到我们要找的对象的引用计数器。
RefcountMap refcnts;
哈希表,key 为 objc_object,即 OC 对象,value 为引用计数。
当 value 为 0 的时候,会将该记录从表中移除。
引用计数器的数据类型是:
typedef __darwin_size_t size_t;
再进一步看它的定义其实是unsigned long,在32位和64位操作系统中,它分别占用32和64个bit。
苹果经常使用bit mask技术。这里也不例外。拿32位系统为例的话,可以理解成有32个盒子排成一排横着放在你面前。盒子里可以装0或者1两个数字。我们规定最后边的盒子是低位,左边的盒子是高位。
(1UL<<0)的意思是将一个"1"放到最右侧的盒子里,然后将这个"1"向左移动0位(就是原地不动):0b0000 0000 0000 0000 0000 0000 0000 0001
(1UL<<1)的意思是将一个"1"放到最右侧的盒子里,然后将这个"1"向左移动1位:0b0000 0000 0000 0000 0000 0000 0000 0010
下面来分析引用计数器(图中右侧)的结构,从低位到高位。
(1UL<<0)????WEAKLY_REFERENCED
表示是否有弱引用指向这个对象,如果有的话(值为1)在对象释放的时候需要把所有指向它的弱引用都变成nil(相当于其他语言的NULL),避免野指针错误。
(1UL<<1)????DEALLOCATING
表示对象是否正在被释放。1正在释放,0没有
(1UL<<(WORD_BITS-1))????SIDE_TABLE_RC_PINNED
其中WORD_BITS在32位和64位系统的时候分别等于32和64。其实这一位没啥具体意义,就是随着对象的引用计数不断变大。如果这一位都变成1了,就表示引用计数已经最大了不能再增加了。
*3、维护weak指针的结构体 weak_table_t weak_table;
第一层结构体中包含两个元素。
第一个元素weak_entry_t *weak_entries;是一个数组,上面RefcountMap是要通过find(key)来找到精确的元素的。weak_entries则是通过循环遍历来找到对应的entry。
(上面管理引用计数器苹果使用的是Map,这里管理weak指针苹果使用的是数组,有兴趣的朋友可以思考一下为什么苹果会分别采用这两种不同的结构)
这个是因为weak的显著的特征来决定的: 当weak对象被销毁的时候,要把所有指向该对象的指针都设为nil。
第二个元素num_entries是用来维护保证数组始终有一个合适的size。比如数组中元素的数量超过3/4的时候将数组的大小乘以2。
第二层weak_entry_t的结构包含3个部分
1、referent:被指对象的地址。前面循环遍历查找的时候就是判断目标地址是否和他相等。
2、referrers:可变数组,里面保存着所有指向这个对象的弱引用的地址。当这个对象被释放的时候,referrers里的所有指针都会被设置成nil。
3、inline_referrers只有4个元素的数组,默认情况下用它来存储弱引用的指针。当大于4个的时候使用referrers来存储指针。
上面我们介绍了苹果为了更好的内存管理使用的三种不同的内存管理方案,在内部采用了不同的数据结构以达到更高效内存检索。