 时间复杂度跟空间复杂度
时间复杂度跟空间复杂度
#
# 时间复杂度
- 事前分析估算法。在计算机程序编制前,依据统计方法对算法进行估算,如根据时间复杂度来估算算法时间效率。
一般情况下,算法中的基本操作语句的重复执行次数是问题规模 n 的某个函数,用 T(n)表示。若有某个辅助函数 f(n),使得当 n 接近于无穷大时,T(n) / f(n)的极限值为不等于零的常数,则称 f(n)是 T(n)的同数量级函数。记作 T(n) = O(f(n))。它表示岁问题规模 n 的增大,算法执行时间的增长率和 f(n)的增长率相同,称作算法的渐进时间复杂度,简称为时间复杂度。这样用大 O()来体现算法时间复杂度的方法,我们称之为大 O 记法。
常见的时间复杂度:
- 常数阶 O(1)
- 对数阶 O(log2n)
- 线性阶 O(n)
- 线性对数阶 O(nlog2n)
- 平方阶 O(n^2)
- 立方阶 O(n^3)
- K 次方阶 O(n^k)
- 指数阶 O(2^n)
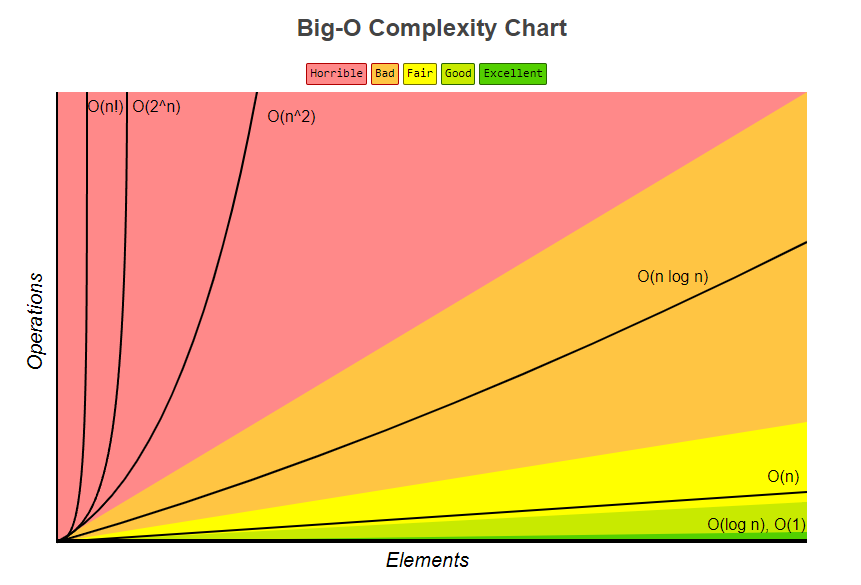
从上往下,时间复杂度依次增大,且随着问题规模 n 的增大,差异愈发明显。常见算法时间复杂度代码示例如下:
# 常数阶O(1):
int a = 0;
int b = 0;
int c = a + b;
2
3
# 线性阶O(n):
线性阶的操作数量相对于输入数据大小n以线性级别增长。线性阶通常出现在单层循环中:
for (int i = 0; i < n; i++){
// 时间复杂度为O(1)的算法
}
2
3
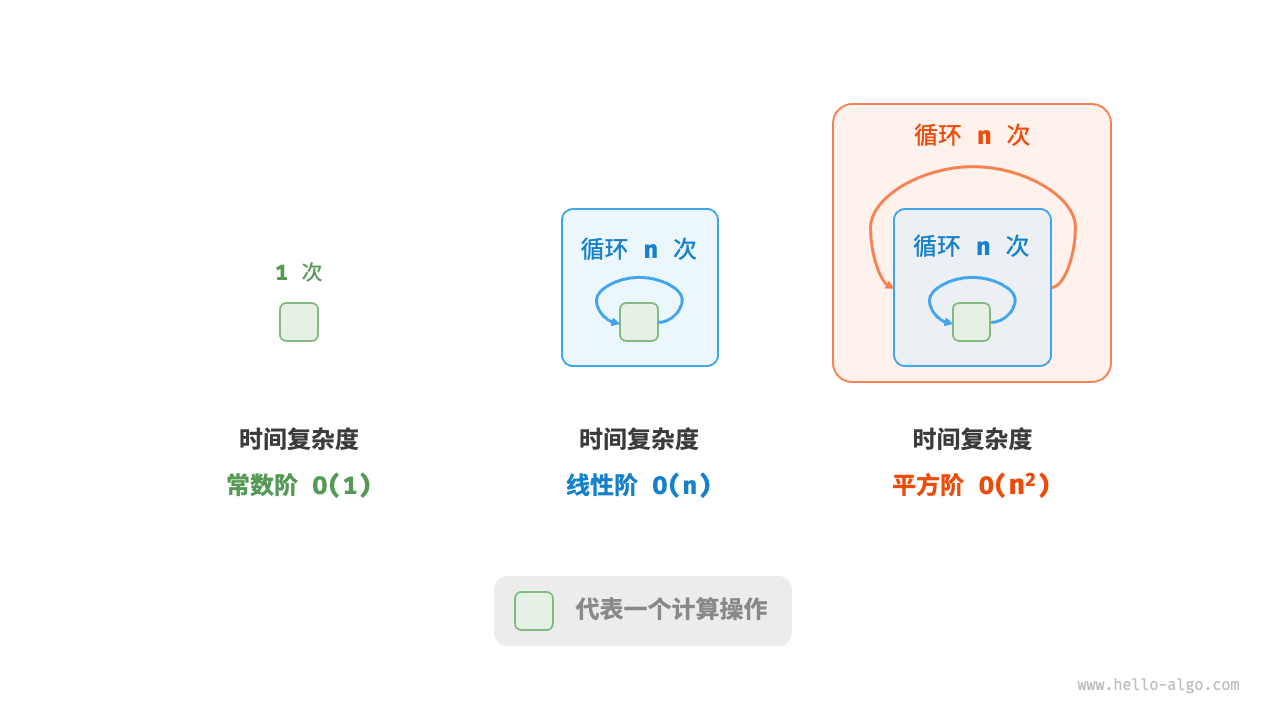
# 平方阶O(n^2):
平方阶的操作数量相对于输入数据大小 以平方级别增长。平方阶通常出现在嵌套循环中,外层循环和内层循环的时间复杂度都为 O(n),因此总体的时间复杂度为 O(n^2):
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++){
// 时间复杂度为O(1)的算法
}
}
2
3
4
5
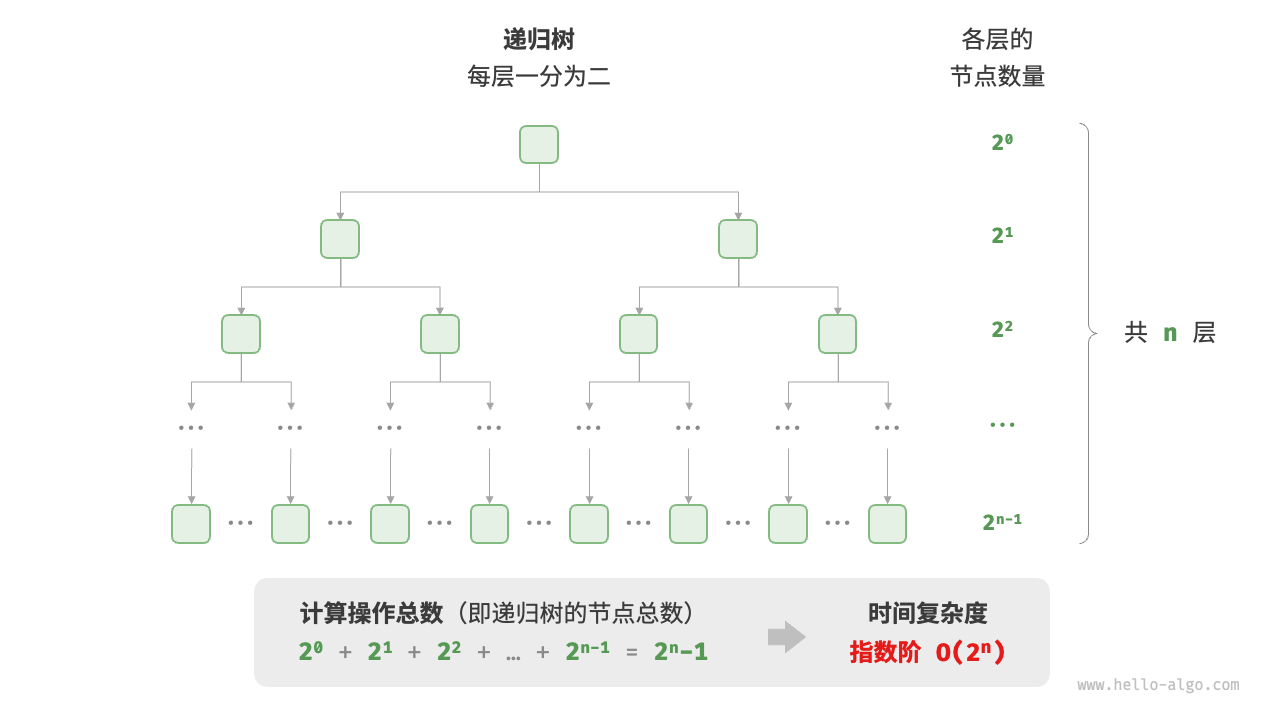
# 指数阶O(2^n):
生物学的“细胞分裂”是指数阶增长的典型例子:初始状态为 1个细胞,分裂一轮后变为 2个,分裂两轮后变为 4个,以此类推,分裂 n轮后有 2^n个细胞。
/* 指数阶(循环实现) */
int exponential(int n) {
int count = 0;
int bas = 1;
// 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
for (int i = 0; i < n; i++) {
for (int j = 0; j < bas; j++) {
count++;
}
bas *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
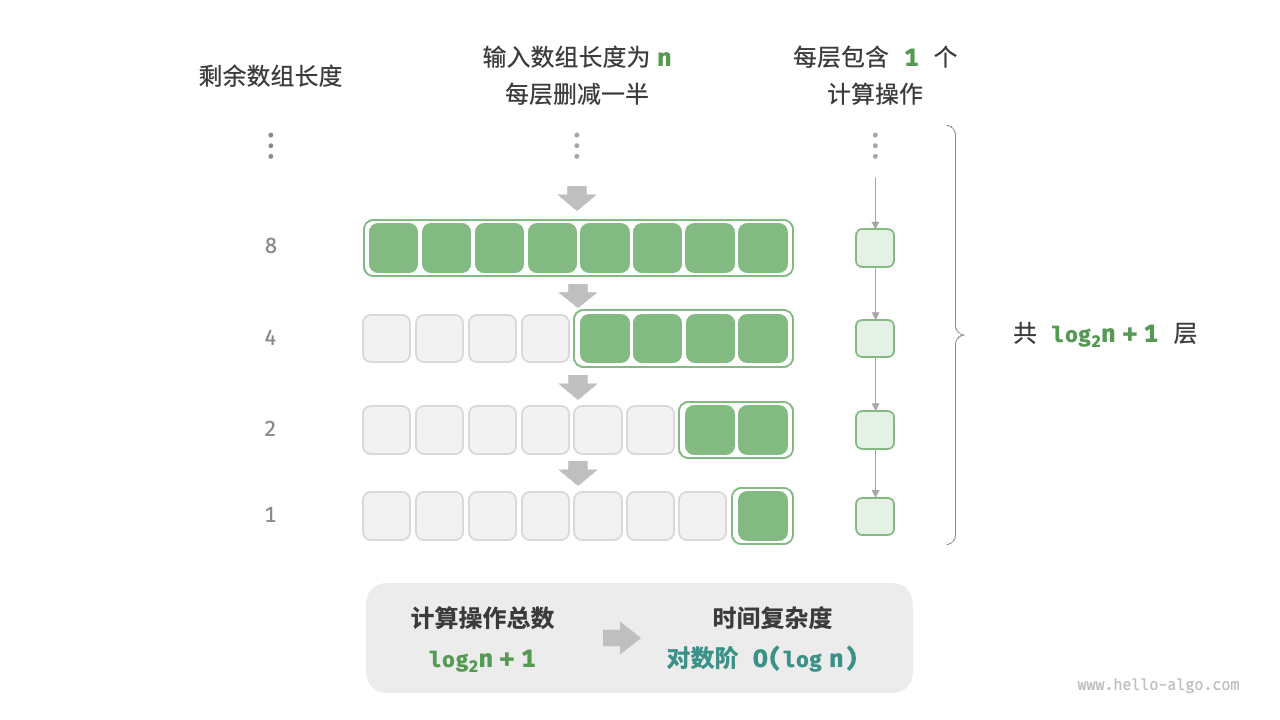
# 对数阶O(logn):
与指数阶相反,对数阶反映了“每轮缩减到一半”的情况。设输入数据大小为n ,由于每轮缩减到一半,因此循环次数是 O(log2n) ,即 2^n的反函数。
对数阶常出现于基于分治策略的算法中,体现了“一分为多”和“化繁为简”的算法思想。它增长缓慢,是仅次于常数阶的理想的时间复杂度。
/* 对数阶(循环实现) */
int logarithmic(int n) {
int count = 0;
while (n > 1) {
n = n / 2;
count++;
}
return count;
}
/* 对数阶(递归实现) */
int logRecur(int n) {
if (n <= 1)
return 0;
return logRecur(n / 2) + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 
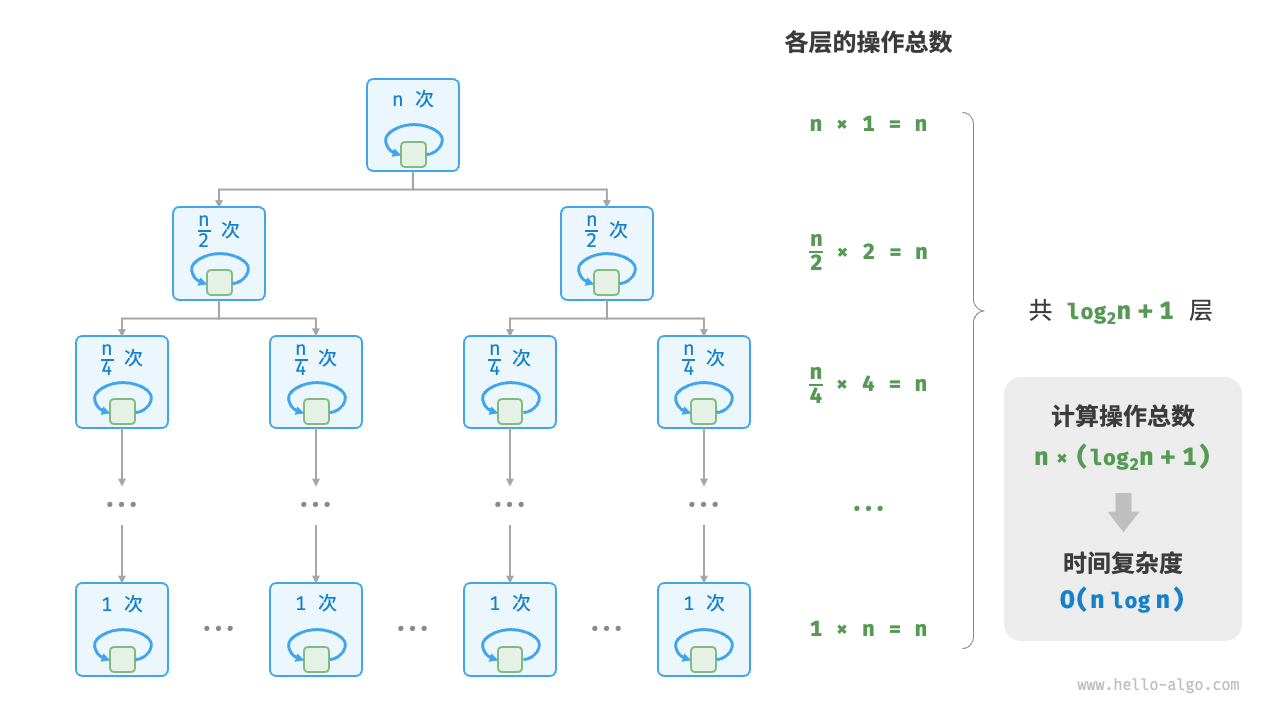
# 线性对数阶 O(nlogn):
线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 和 。相关代码如下:
for (int j = 0; j < n; j++){
int i = n;
while(i < n){
// 时间复杂度为O(1)的算法
}
}
2
3
4
5
6
7
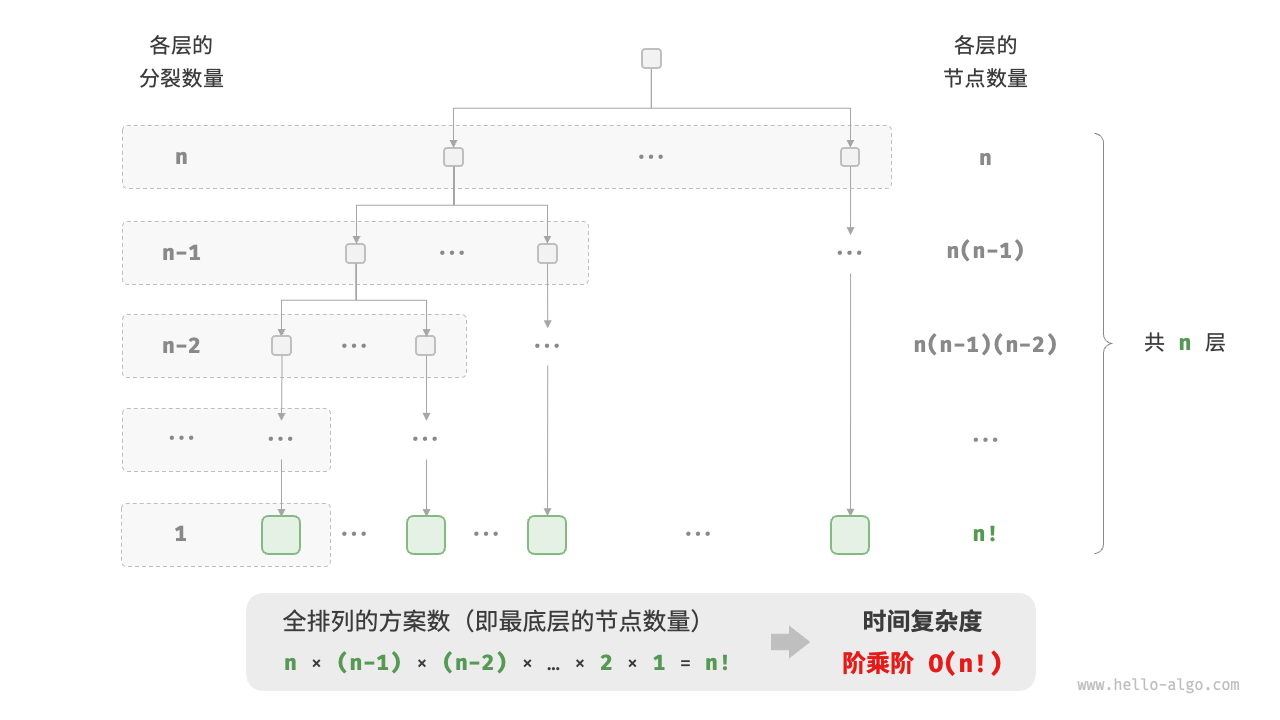
# 阶乘阶O(n!)
阶乘阶对应数学上的“全排列”问题。给定 个互不重复的元素,求其所有可能的排列方案,方案数量为:
阶乘通常使用递归实现。如图 2-14 和以下代码所示,第一层分裂出 个,第二层分裂出 个,以此类推,直至第 层时停止分裂:
/* 阶乘阶(递归实现) */
int factorialRecur(int n) {
if (n == 0)
return 1;
int count = 0;
for (int i = 0; i < n; i++) {
count += factorialRecur(n - 1);
}
return count;
}
2
3
4
5
6
7
8
9
10
# 2.3.5 最差、最佳、平均时间复杂度
算法的时间效率往往不是固定的,而是与输入数据的分布有关。假设输入一个长度为 的数组 nums ,其中 nums 由从 至 的数字组成,每个数字只出现一次;但元素顺序是随机打乱的,任务目标是返回元素 的索引。我们可以得出以下结论。
- 当
nums = [?, ?, ..., 1],即当末尾元素是 时,需要完整遍历数组,达到最差时间复杂度 。 - 当
nums = [1, ?, ?, ...],即当首个元素为 时,无论数组多长都不需要继续遍历,达到最佳时间复杂度 。
“最差时间复杂度”对应函数渐近上界,使用大 记号表示。相应地,“最佳时间复杂度”对应函数渐近下界,用 记号表示:
最坏时间复杂度 & 平均时间复杂度:
最坏时间复杂度是指的是在最坏情况下的时间复杂度,可以保证算法在任何输入情况下都不会比最坏时间复杂度更糟糕。我们通常所说的时间复杂度都是最坏时间复杂度。平均时间复杂度就是从概率的角度,计算所有输入情况下的平均时间。
# 空间复杂度
算法的空间复杂度通过计算算法所需的存储空间实现的。和时间复杂度类似,记作:S(n) = O(f(n)),其中 n 为问题的规模,f(n)为关于 n 所占存储空间的函数。
时间复杂度指的是对运行时间的需求,空间复杂度指的是对运行空间的需求。在实际工作中通常会使用空间换时间的做法,所以我们一般讨论的复杂度都是时间复杂度。
常用数据结构操作复杂度:

数组排序复杂度: