程序执行的流程
程序执行的流程
# 一个程序从编译到运行的全过程
一个程序,从编写完代码,到被计算机运行,总共需要经历以下四步:
- 编译。编译器会将程序源代码编译成汇编代码。
- 汇编。汇编器会将汇编代码文件翻译成为二进制的机器码。
- 链接。链接器会将一个个目标文件和库文件链接在一起,成为一个完整的可执行程序。
- 载入。加载器会将可执行文件的代码和数据从硬盘加载到内存中,然后跳转到程序的第一条指令处开始运行。
链接器和加载器是由操作系统实现的程序。而编译器和汇编器则是由不同的编程语言自己实现的了。
这里需要展开来说一说,我们常用的高级语言,按照转化成机器码的方式不同可以分为编译型语言和解释型语言,
编译型语言要求由编译器提前将源代码一次性转换成二进制指令,即生成一个可执行程序,后续的执行无需重新编译。比如我们常见的 C、Golang 等,优点是执行效率高;缺点是可执行程序不能跨平台(不同的操作系统对不同的可执行文件的内部结构要求不同;另外,由于不同操作系统支持的函数等也可能不同,所以部分源代码也不能跨平台)。 解释型语言不需要提前编译,程序只在运行时才由解释器翻译成机器码,每执行依次就要翻译一次。比如我们常见的 Python、PHP 等,优点是较方便(对编写用户而言,省去了编译的步骤),实时性高(每次修改代码后都可直接运行),能跨平台;缺点是效率低。
半编译半解释型语言:还有一类比较特殊,混合了两种方式。源代码需要先编译成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中解释执行。比如我们常见的 Java、C# 等。 所以,要设计一门语言,还必须为其编写相应的编译器和解释器,将源代码转化为计算机可执行的机器码。由于不同的语言有不同的转化方式,接下来将以最常见的 C 语言为例,简单分析一下 编译→汇编→链接→载入 的过程。
总结:不同的语言会使用不同的方式将源代码转化为机器码,但是之后的链接和载入过程都是由操作系统完成的,都是相同的。
# 编译
编译是读取源程序,进行词法和语法分析,将高级语言代码转换为汇编代码。整个编译过程可以分为两个阶段。
# 预处理
- 对其中的伪指令(以 # 开头的指令)进行处理。
- 将所有的 #define 删除,并且展开所有的宏定义;
- 处理条件编译指令,如 #if、#elif、#else、endif 等;
- 处理头文件包含指令,如 #include,将被包含的文件插入到该预编译指令的位置;
删除所有的注释。 添加行号和文件名标识。
# 编译
对预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后,产生相应的汇编代码文件。
# 汇编
将编译完的汇编代码文件翻译成机器指令,保存在后缀为 .o 的目标文件(Object File)中。
这个文件是一个 ELF 格式的文件(Executable and Linkable Format,可执行可链接文件格式),包括可以被执行的文件和可以被链接的文件(如目标文件 .o,可执行文件 .exe,共享目标文件 .so),有其固定的格式。
# 链接
由汇编程序生成的目标文件并不能被立即执行,还需要通过链接器(Linker),将有关的目标文件彼此相连接,使得所有的目标文件成为一个能够被操作系统载入执行的统一整体。
例如在某个源文件的函数中调用了另一个源文件中的函数;或者调用了库文件中的函数等等情况,都需要经过链接才能使用。 链接处理可以分为两种:
静态链接:直接在编译阶段就把静态库加入到可执行文件当中去。优点:不用担心目标用户缺少库文件。缺点:最终的可执行文件会较大;且多个应用程序之间无法共享库文件,会造成内存浪费。
动态链接:在链接阶段只加入一些描述信息,等到程序执行时再从系统中把相应的动态库加载到内存中去。优点:可执行文件小;多个应用程序之间可以共享库文件。缺点:需要保证目标用户有相应的库文件。
# 载入
加载器(Loader)会将可执行文件的代码和数据加载到内存(虚拟内存)中,然后跳转到程序的第一条指令开始执行程序。
说起来只是装载到内存中去那么简单的一句话,可是其实要是展开来说,会涉及到整个操作系统的内存管理。
可执行文件载入内存的过程可以概括为以下几步:
- 给进程分配虚拟内存空间;
- 创建虚拟地址到物理地址的映射,创建页表;
- 加载代码段和数据段等数据,即将硬盘中的文件拷贝到物理内存页中,并在页表中写入映射关系;
- 把可执行文件的入口地址写入到 CPU 的 指令寄存器(PC)中,即可执行程序。
# CPU的组成
CPU是由四大部分所构成的:寄存器、控制器、运算器、时钟。
寄存器
CPU内部的内存,程序加载进CPU内部的寄存器中从而被用来解释和运行。
控制器
计算机的指挥中心,负责决定执行程序的顺序,给出执行指令时机器各部件需要的操作控制命令。
运算器
计算机中执行各种算术和逻辑运算操作的部件。
时钟
它是处理操作的最基本的单位,影响着指令的取出和执行时间。
# 南桥&北桥
北桥其实就是一个计算机结构,准确地说是一个芯片,它连接的都是高速设备,通过PCI总线,把cpu、内存、显卡串在一起
南桥就要慢很多了,连接的都是鼠标、键盘、硬盘等这些“穷慢”亲戚,它们之间用ISA总线串在一起。
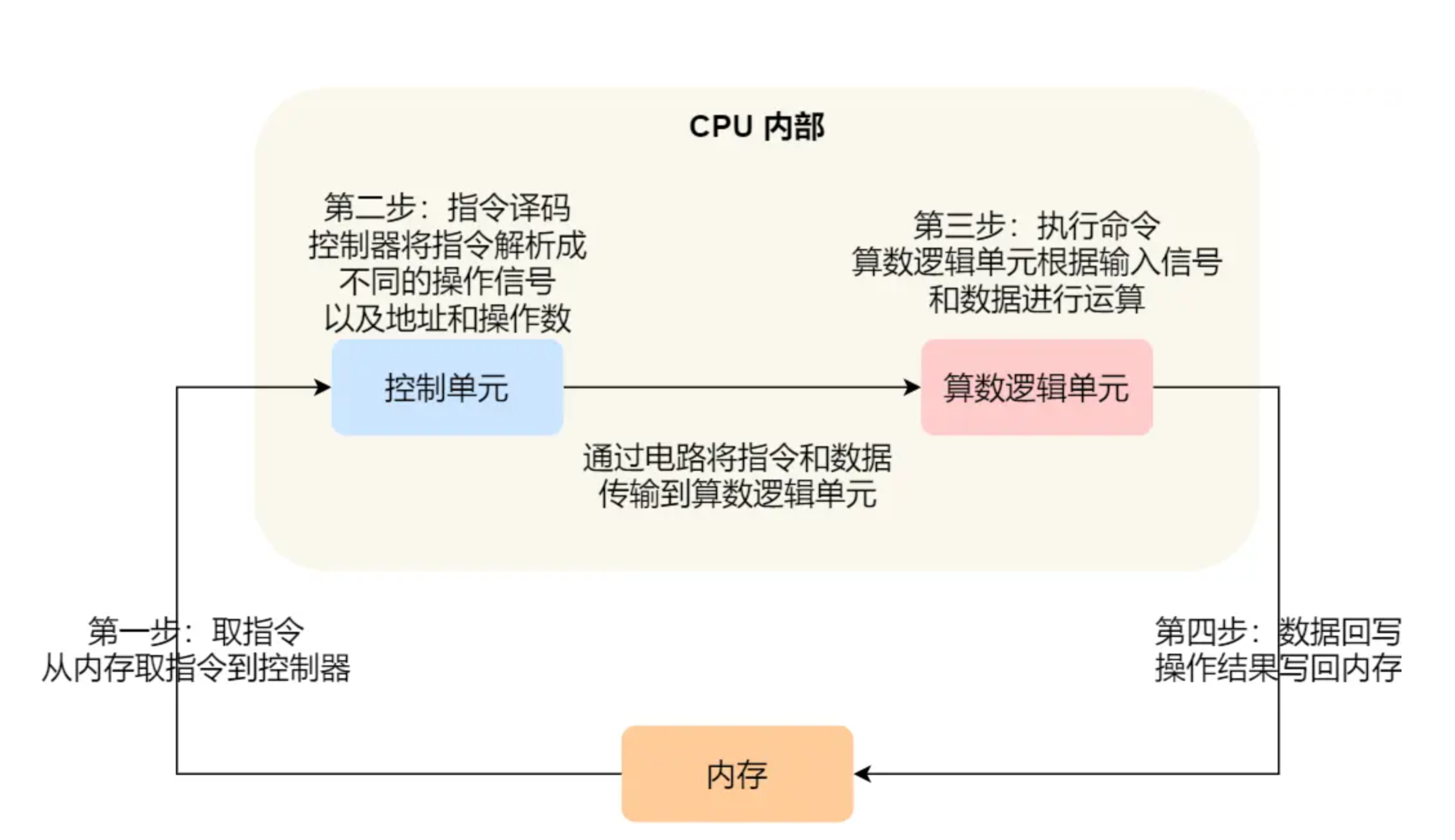
# CPU 执行程序的过程如下
第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
第二步,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
第三步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
现代大多数 CPU 都使用来流水线的方式来执行指令,所谓的流水线就是把一个任务拆分成多个小任务,于是一条指令通常分为 4 个阶段,称为 4 级流水线
四个阶段的具体含义:
CPU 通过程序计数器读取对应内存地址的指令,这个部分称为 Fetch(取得指令);
CPU 对指令进行解码,这个部分称为 Decode(指令译码);
CPU 执行指令,这个部分称为 Execution(执行指令);
CPU 将计算结果存回寄存器或者将寄存器的值存入内存,这个部分称为 Store(数据回写);